
MIX Fold3包裝盒泄露 新機本月登場
小米的全新折疊屏旗艦MIX Fold3將于本月發布,近日該機的真機包裝盒在網上泄露。從圖上來看,新的MIX Fold3包裝盒在外觀設計方面延續了之前的方案,變化不大,這也是目前小米旗艦
在編程社區中,眾所周知Python編程語言在速度方面并不占優勢。
"但是就是慢..."
在這篇文章中,我將介紹Python的不同特性,我們將了解為什么這使其成為當今最完整的語言之一,但速度不夠快。但首先,讓我們掌握一些關于編程語言的基本知識。

正如我們可能知道的那樣,編程語言通常根據其抽象級別進行描述。
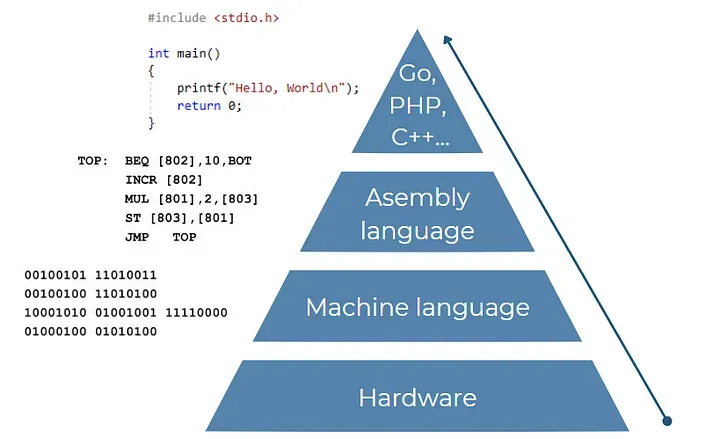
抽象級別(從硬件到現代編程語言)
C++、PHP、Java、Python等都被認為是現代(或高級)編程語言,因為它們可以在幾乎任何類型的系統上運行。在匯編語言中,我們必須根據每個特定處理器的指令編寫不同的程序(無法在不同的CPU上運行相同的代碼)。例如,如果我們創建一個打印“Hello world”的程序并將代碼發送給我們的朋友(他有不同的計算機型號),當他嘗試執行它時,它可能會失敗。

現代語言抽象
盡管是離機器碼最高的抽象,但在金字塔的最后一層也有層次結構。一方面,我們可以找到過程化語言,如C,我們需要逐步知道自己在做什么。這具有非常高效的優點,但缺點是復雜且不夠靈活。另一方面,其他語言通過讓我們使用更易讀和靈活的代碼來簡化任務。這就是Python的情況。我們幾乎可以用它做任何事情,而且易于實現,但在某些任務上效率不高。
但為什么Python確切地說是“慢”呢?
讓我們回顧一些語言特性以回答這個問題。
首先,Python是一種解釋性語言,這意味著代碼由軟件程序(稱為解釋器)逐行讀取和執行,在運行時進行。這是將代碼轉換為機器代碼的一種方式。
另一種使代碼“為機器可理解”的方式是通過編譯過程。在這種情況下,源代碼在實際在計算機上運行之前通過編譯器轉換為機器代碼。
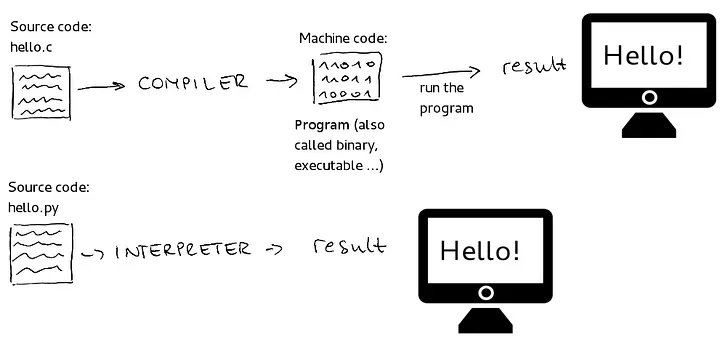
編譯型與解釋型語言
在解釋性語言中,源代碼的每一行在執行過程中都會即時轉換為機器代碼。這意味著每次程序運行時,解釋器必須解析、分析和執行代碼,這增加了與直接運行預編譯機器代碼相比的開銷。例如:如果某段代碼運行多次(例如,在循環內),解釋器必須每次遇到時讀取和轉換它。相反,編譯程序將直接運行機器代碼,無需在通過循環時重新翻譯它。
標準的Python解釋器是CPython。它由C和Python編寫,將Python代碼編譯成字節碼,然后進行解釋。為了防止多個本機線程同時執行Python字節碼,CPython使用全局解釋器鎖。這個鎖是必要的,因為CPython的內存管理不是線程安全的。然而,在多線程程序中,它可能是一個顯著的瓶頸,限制了在多核處理器上進行多線程的性能提升。
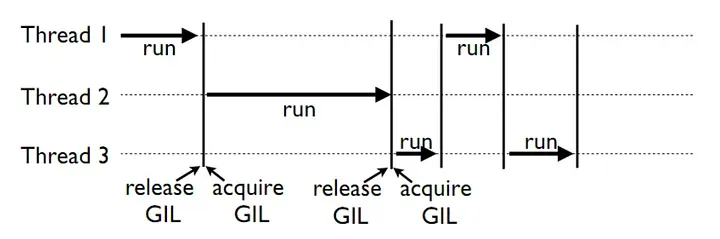
全局解釋器鎖的工作流程
此外,Python是動態類型的,這意味著在初始化變量時不需要聲明變量的類型。這對效率有何影響呢?嗯,在動態類型語言中,類型是在運行時確定的。這意味著解釋器需要在執行代碼片段時進行類型檢查。這需要額外的處理來確定每個變量的類型以及根據這些類型執行操作的方式。而動態類型語言的對立面是什么?
在這種情況下,變量的類型在編譯時而不是在運行時確定。因此,類型在編譯時已知,編譯器可以更激進地優化代碼執行。這導致更快但不夠靈活的程序。一些采用這種方法的語言包括C++和Rust。
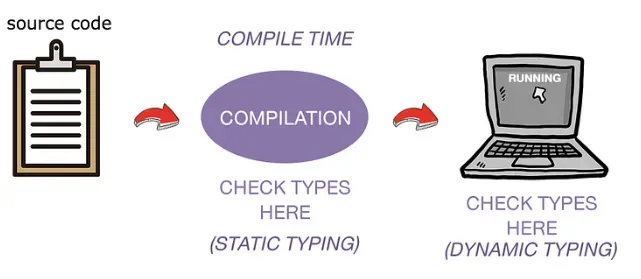
靜態類型與動態類型語言
垃圾收集是一種編程語言運行時系統用于回收程序不再使用的內存的自動內存管理形式。Python通過垃圾收集自動管理其對象的內存分配和釋放。它使用的主要垃圾收集方法是引用計數。Python中的每個對象都有一個引用計數,即指向它的引用數量。當引用計數降至零,即不再有指向該對象的引用時,它會立即從內存中刪除。
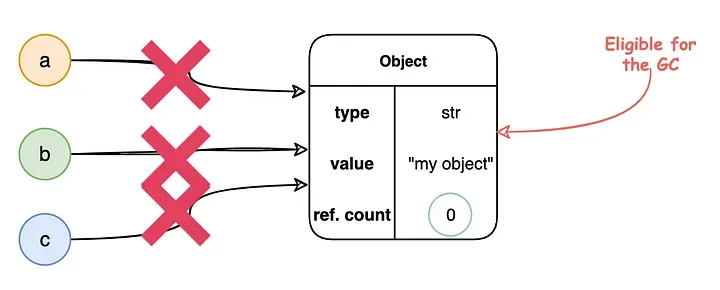
垃圾收集器的工作流程
然而,垃圾收集是一把雙刃劍...
它通過自動清理未使用的對象極大簡化了內存管理,有助于防止由于手動內存管理導致的內存泄漏和其他錯誤。但它引入了開銷和不可預測性,可能影響應用程序的性能。
本文鏈接:http://www.tebozhan.com/showinfo-26-92126-0.html一文看懂,為什么 Python 運行速度如此慢?
聲明:本網頁內容旨在傳播知識,若有侵權等問題請及時與本網聯系,我們將在第一時間刪除處理。郵件:2376512515@qq.com
上一篇: C# new 關鍵字的三種用法
Copyright ? 2016-2023 天津谷騏科技有限公司 版權所有 sitemap.xml
違法及侵權請聯系:2376512515@qq.com 津ICP備18001702號
 津公網安備 12010102000574號
津公網安備 12010102000574號