
十個可以手動編寫的 JavaScript 數組 API
JavaScript 中有很多API,使用得當,會很方便,省力不少。 你知道它的原理嗎? 今天這篇文章,我們將對它們進行一次小總結。現在開始吧。1.forEach()forEach()用于遍歷數組接收一參
注意力機制是許多最先進神經網絡架構的基本組成部分,比如Transformer模型。注意力機制中的一個關鍵方面是掩碼,它有助于控制信息流,并確保模型適當地處理序列。

在這篇文章中,我們將探索在注意力機制中使用的各種類型的掩碼,并在PyTorch中實現它們。
在神經網絡中,掩碼是一種用于阻止模型使用輸入數據中的某些部分的技術。這在序列模型中尤其重要,因為序列的長度可能會有所不同,且輸入的某些部分可能無關緊要(例如,填充符)或需要被隱藏(例如,語言建模中的未來內容)。
在深度學習中,特別是在處理序列數據時,"填充掩碼"(Padding Mask)是一個重要概念。當序列數據的長度不一致時,通常需要對短的序列進行填充(padding),以確保所有序列的長度相同,這樣才能進行批處理。這些填充的部分實際上是沒有任何意義的,不應該對模型的學習產生影響。
序列掩碼用于隱藏輸入序列的某些部分。比如在雙向模型中,想要根據特定標準忽略序列的某些部分。
前瞻掩碼,也稱為因果掩碼或未來掩碼,用于自回歸模型中,以防止模型在生成序列時窺視未來的符號。這確保了給定位置的預測僅依賴于該位置之前的符號。
填充掩碼就是用來指示哪些數據是真實的,哪些是填充的。在模型處理這些數據時,掩碼會用來避免在計算損失或者梯度時考慮填充的部分,確保模型的學習只關注于有效的數據。在使用諸如Transformer這樣的模型時,填充掩碼特別重要,因為它們可以幫助模型在進行自注意力計算時忽略掉填充的位置。
import torch def create_padding_mask(seq, pad_token=0): mask = (seq == pad_token).unsqueeze(1).unsqueeze(2) return mask # (batch_size, 1, 1, seq_len) # Example usage seq = torch.tensor([[7, 6, 0, 0], [1, 2, 3, 0]]) padding_mask = create_padding_mask(seq) print(padding_mask)
在使用如Transformer模型時,序列掩碼用于避免在計算注意力分數時考慮到填充位置的影響。這確保了模型的注意力是集中在實際有意義的數據上,而不是無關的填充數據。
RNNs本身可以處理不同長度的序列,但在批處理和某些架構中,仍然需要固定長度的輸入。序列掩碼在這里可以幫助RNN忽略掉序列中的填充部分,特別是在計算最終序列輸出或狀態時。
在訓練模型時,序列掩碼也可以用來確保在計算損失函數時,不會將填充部分的預測誤差納入總損失中,從而提高模型訓練的準確性和效率。
序列掩碼通常表示為一個與序列數據維度相同的二進制矩陣或向量,其中1表示實際數據,0表示填充數據
def create_sequence_mask(seq): seq_len = seq.size(1) mask = torch.triu(torch.ones((seq_len, seq_len)), diagonal=1) return mask # (seq_len, seq_len) # Example usage seq_len = 4 sequence_mask = create_sequence_mask(torch.zeros(seq_len, seq_len)) print(sequence_mask)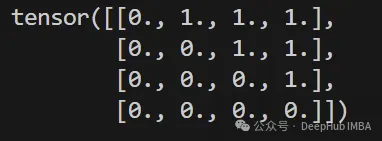
前瞻掩碼通過在自注意力機制中屏蔽(即設置為一個非常小的負值,如負無窮大)未來時間步的信息來工作。這確保了在計算每個元素的輸出時,模型只能使用到當前和之前的信息,而不能使用后面的信息。這種機制對于保持自回歸屬性(即一次生成一個輸出,且依賴于前面的輸出)是必要的。
在實現時,前瞻掩碼通常表示為一個上三角矩陣,其中對角線及對角線以下的元素為0(表示這些位置的信息是可見的),對角線以上的元素為1(表示這些位置的信息是不可見的)。在計算注意力時,這些為1的位置會被設置為一個非常小的負數(通常是負無窮),這樣經過softmax函數后,這些位置的權重接近于0,從而不會對輸出產生影響。
def create_look_ahead_mask(size): mask = torch.triu(torch.ones(size, size), diagonal=1) return mask # (seq_len, seq_len) # Example usage look_ahead_mask = create_look_ahead_mask(4) print(look_ahead_mask)
填充掩碼(Padding Mask)和序列掩碼(Sequence Mask)都是在處理序列數據時使用的技術,它們的目的是幫助模型正確處理變長的輸入序列,但它們的應用場景和功能有些區別。這兩種掩碼經常在深度學習模型中被一起使用,尤其是在需要處理不同長度序列的場景下。
填充掩碼專門用于指示哪些數據是填充的,這主要應用在輸入數據預處理和模型的輸入層。其核心目的是確保模型在處理或學習過程中不會將填充部分的數據當作有效數據來處理,從而影響模型的性能。在諸如Transformer模型的自注意力機制中,填充掩碼用于阻止模型將注意力放在填充的序列上。
序列掩碼通常用于更廣泛的上下文中,它不僅可以指示填充位置,還可以用于其他類型的掩蔽,如在序列到序列的任務中掩蔽未來的信息(如解碼器的自回歸預測)。序列掩碼可以用于確保模型在處理過程中只關注于當前及之前的信息,而不是未來的信息,這對于保持信息的時序依賴性非常重要。
充掩碼多用于模型的輸入階段或在注意力機制中排除無效數據的影響,序列掩碼則可能在模型的多個階段使用,特別是在需要控制信息流的場景中。
與填充掩碼和序列掩碼不同,前瞻掩碼專門用于控制時間序列的信息流,確保在生成序列的每個步驟中模型只能利用到當前和之前的信息。這是生成任務中保持模型正確性和效率的關鍵技術。
在注意力機制中,掩碼被用來修改注意力得分。
import torch.nn.functional as F def scaled_dot_product_attention(q, k, v, mask=None): matmul_qk = torch.matmul(q, k.transpose(-2, -1)) dk = q.size()[-1] scaled_attention_logits = matmul_qk / torch.sqrt(torch.tensor(dk, dtype=torch.float32)) if mask is not None: scaled_attention_logits += (mask * -1e9) attention_weights = F.softmax(scaled_attention_logits, dim=-1) output = torch.matmul(attention_weights, v) return output, attention_weights # Example usage d_model = 512 batch_size = 2 seq_len = 4 q = torch.rand((batch_size, seq_len, d_model)) k = torch.rand((batch_size, seq_len, d_model)) v = torch.rand((batch_size, seq_len, d_model)) mask = create_look_ahead_mask(seq_len) attention_output, attention_weights = scaled_dot_product_attention(q, k, v, mask) print(attention_output)import torch.nn.functional as F def scaled_dot_product_attention(q, k, v, mask=None): matmul_qk = torch.matmul(q, k.transpose(-2, -1)) dk = q.size()[-1] scaled_attention_logits = matmul_qk / torch.sqrt(torch.tensor(dk, dtype=torch.float32)) if mask is not None: scaled_attention_logits += (mask * -1e9) attention_weights = F.softmax(scaled_attention_logits, dim=-1) output = torch.matmul(attention_weights, v) return output, attention_weights # Example usage d_model = 512 batch_size = 2 seq_len = 4 q = torch.rand((batch_size, seq_len, d_model)) k = torch.rand((batch_size, seq_len, d_model)) v = torch.rand((batch_size, seq_len, d_model)) mask = create_look_ahead_mask(seq_len) attention_output, attention_weights = scaled_dot_product_attention(q, k, v, mask) print(attention_output)
我們創建一個簡單的Transformer 層來驗證一下三個掩碼的不同之處:
import torch import torch.nn as nn class MultiHeadAttention(nn.Module): def __init__(self, d_model, num_heads): super(MultiHeadAttention, self).__init__() self.num_heads = num_heads self.d_model = d_model assert d_model % num_heads == 0 self.depth = d_model // num_heads self.wq = nn.Linear(d_model, d_model) self.wk = nn.Linear(d_model, d_model) self.wv = nn.Linear(d_model, d_model) self.dense = nn.Linear(d_model, d_model) def split_heads(self, x, batch_size): x = x.view(batch_size, -1, self.num_heads, self.depth) return x.permute(0, 2, 1, 3) def forward(self, v, k, q, mask): batch_size = q.size(0) q = self.split_heads(self.wq(q), batch_size) k = self.split_heads(self.wk(k), batch_size) v = self.split_heads(self.wv(v), batch_size) scaled_attention, _ = scaled_dot_product_attention(q, k, v, mask) scaled_attention = scaled_attention.permute(0, 2, 1, 3).contiguous() original_size_attention = scaled_attention.view(batch_size, -1, self.d_model) output = self.dense(original_size_attention) return output class TransformerLayer(nn.Module): def __init__(self, d_model, num_heads, dff, dropout_rate=0.1): super(TransformerLayer, self).__init__() self.mha = MultiHeadAttention(d_model, num_heads) self.ffn = nn.Sequential( nn.Linear(d_model, dff), nn.ReLU(), nn.Linear(dff, d_model) ) self.layernorm1 = nn.LayerNorm(d_model) self.layernorm2 = nn.LayerNorm(d_model) self.dropout1 = nn.Dropout(dropout_rate) self.dropout2 = nn.Dropout(dropout_rate) def forward(self, x, mask): attn_output = self.mha(x, x, x, mask) attn_output = self.dropout1(attn_output) out1 = self.layernorm1(x + attn_output) ffn_output = self.ffn(out1) ffn_output = self.dropout2(ffn_output) out2 = self.layernorm2(out1 + ffn_output) return out2創建一個簡單的模型:
d_model = 512 num_heads = 8 dff = 2048 dropout_rate = 0.1 batch_size = 2 seq_len = 4 x = torch.rand((batch_size, seq_len, d_model)) mask = create_padding_mask(torch.tensor([[1, 2, 0, 0], [3, 4, 5, 0]])) transformer_layer = TransformerLayer(d_model, num_heads, dff, dropout_rate) output = transformer_layer(x, mask)然后在Transformer層上運行我們上面介紹的三個掩碼。
def test_padding_mask(): seq = torch.tensor([[7, 6, 0, 0], [1, 2, 3, 0]]) expected_mask = torch.tensor([[[[0, 0, 1, 1]]], [[[0, 0, 0, 1]]]]) assert torch.equal(create_padding_mask(seq), expected_mask) print("Padding mask test passed!") def test_sequence_mask(): seq_len = 4 expected_mask = torch.tensor([[0, 1, 1, 1], [0, 0, 1, 1], [0, 0, 0, 1], [0, 0, 0, 0]]) assert torch.equal(create_sequence_mask(torch.zeros(seq_len, seq_len)), expected_mask) print("Sequence mask test passed!") def test_look_ahead_mask(): size = 4 expected_mask = torch.tensor([[0, 1, 1, 1], [0, 0, 1, 1], [0, 0, 0, 1], [0, 0, 0, 0]]) assert torch.equal(create_look_ahead_mask(size), expected_mask) print("Look-ahead mask test passed!") def test_transformer_layer(): d_model = 512 num_heads = 8 dff = 2048 dropout_rate = 0.1 batch_size = 2 seq_len = 4 x = torch.rand((batch_size, seq_len, d_model)) mask = create_padding_mask(torch.tensor([[1, 2, 0, 0], [3, 4, 5, 0]])) transformer_layer = TransformerLayer(d_model, num_heads, dff, dropout_rate) output = transformer_layer(x, mask) assert output.size() == (batch_size, seq_len, d_model) print("Transformer layer test passed!") test_padding_mask() test_sequence_mask() test_look_ahead_mask() test_transformer_layer()結果和上面我們單獨執行是一樣的,所以得到如下結果

最后我們來做個總結,在自然語言處理和其他序列處理任務中,使用不同類型的掩碼來管理和優化模型處理信息的方式是非常關鍵的。這些掩碼主要包括填充掩碼、序列掩碼和前瞻掩碼,每種掩碼都有其特定的使用場景和目的。
這些掩碼在處理變長序列、保持模型效率和正確性方面扮演著重要角色,是現代深度學習模型不可或缺的一部分。在設計和實現模型時,合理地使用這些掩碼可以顯著提高模型的性能和輸出質量。
本文鏈接:http://www.tebozhan.com/showinfo-26-101115-0.html注意力機制中三種掩碼技術詳解和Pytorch實現
聲明:本網頁內容旨在傳播知識,若有侵權等問題請及時與本網聯系,我們將在第一時間刪除處理。郵件:2376512515@qq.com
上一篇: 一圖看懂八大擴展系統的方法
下一篇: 協方差矩陣適應進化算法實現高效特征選擇
Copyright ? 2016-2023 天津谷騏科技有限公司 版權所有 sitemap.xml
違法及侵權請聯系:2376512515@qq.com 津ICP備18001702號
 津公網安備 12010102000574號
津公網安備 12010102000574號