
中興AX5400Pro+上手體驗:再升級 雙2.5G網(wǎng)口+USB 3.0這次全都有
2021年11月的時候,中興先后發(fā)布了兩款路由器產(chǎn)品,中興AX5400和中興AX5400 Pro,從產(chǎn)品命名上就不難看出這是隸屬于同一系列的,但在外觀設(shè)計上這兩款產(chǎn)品可以說是完全沒一點關(guān)系
Spring Data JPA 是一個強大的工具,用于在 Java 應用程序中處理數(shù)據(jù)庫。它為查詢和持久化數(shù)據(jù)提供了一個易于使用且靈活的接口,并且可以顯著簡化數(shù)據(jù)訪問層。但是,如同其他工具一樣,正確使用 Spring Data JPA 來獲得最佳性能和效率非常重要。
在本文中,我們將探索使用 Spring Data JPA 優(yōu)化性能的一些技巧和最佳實踐。
N+1查詢問題是指在使用延遲加載機制時,當我們查詢一個實體對象及其關(guān)聯(lián)對象時,由于需要每次查詢相應的關(guān)聯(lián)對象,所以就會發(fā)生多次查詢數(shù)據(jù)庫的情況。例如,我們查詢一個包含 N 個訂單的用戶,而每個訂單又包含 M 個商品,則會發(fā)生 (N+1)*M 次查詢數(shù)據(jù)庫的情況,其中 N+1 是因為查詢用戶時也需要進行一次查詢。
這種情況下,當數(shù)據(jù)量較大時,就會導致性能問題和資源浪費。因此,在使用
Spring Data JPA 時,應注意避免 N+1 查詢問題,從而提高查詢效率。
解決 N+1 查詢問題有以下幾種方式:
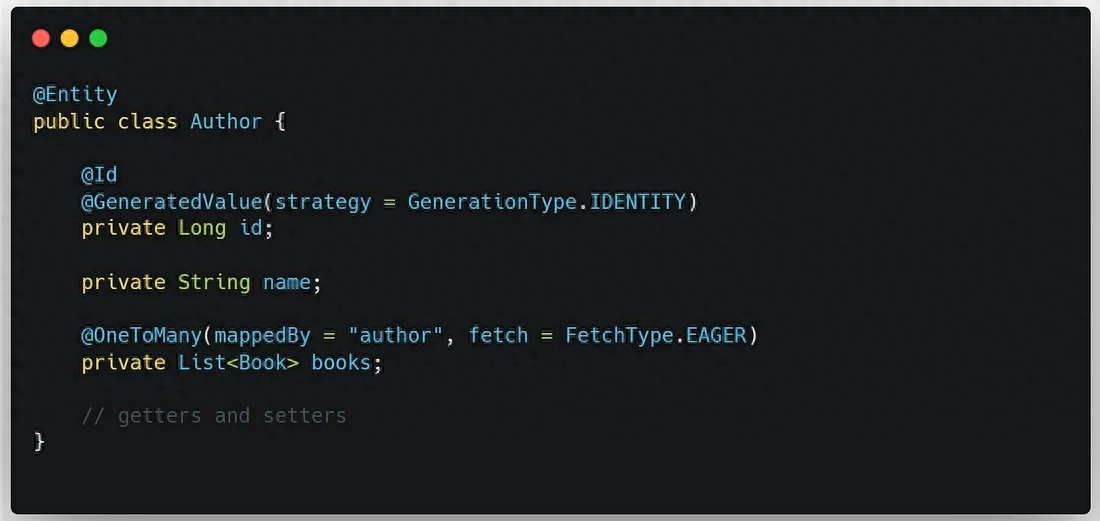
在定義實體類時,可以使用 @OneToMany 或 @ManyToOne 注解中的 fetch 屬性將關(guān)聯(lián)對象改為即時加載模式。但需要注意,如果關(guān)聯(lián)對象數(shù)量較大,可能會影響性能。

@BatchSize 注解可以控制 Hibernate 在加載關(guān)聯(lián)對象時一次性加載的個數(shù)。例如,設(shè)置 @BatchSize(size = 100) 后,Hibernate 將會在一次查詢中加載 100 個關(guān)聯(lián)對象。
使用 JPQL(Java Persistence Query Language)或 Criteria API 構(gòu)建查詢語句時,可以使用 JOIN FETCH 關(guān)鍵字來實現(xiàn)關(guān)聯(lián)查詢,從而一次性加載關(guān)聯(lián)對象。
EntityGraph 是 JPA 2.1 中引入的一種機制,可以預定義實體類的加載圖(Load Graph),并在查詢時指定該加載圖,從而控制關(guān)聯(lián)對象的加載方式。例如,可以使用 @NamedEntityGraph 注解在實體類上定義加載圖,然后在查詢時使用 @EntityGraph 注解指定該加載圖。
需要注意的是,采用以上幾種方式來解決 N+1 查詢問題時,需要根據(jù)具體情況進行選擇和調(diào)整,避免出現(xiàn)新的性能問題。
延遲加載是一種將對象或數(shù)據(jù)的加載延遲到需要時才加載的技術(shù)。換句話說,延遲加載不是一次加載所有數(shù)據(jù),而是在請求時只加載所需的數(shù)據(jù)。這可以通過減少加載到內(nèi)存中的不必要數(shù)據(jù)量來節(jié)省大量時間和資源。
Spring Data JPA 支持兩種加載方式:即時加載(Eager loading)和延遲加載(Lazy loading)。即時加載是指在查詢實體對象時,將其關(guān)聯(lián)的所有對象都一并加載;而延遲加載則是指只有在需要使用到關(guān)聯(lián)對象時才進行加載。
下面是使用 Spring Data JPA 延遲加載的示例代碼:
@Entitypublic class Order { @Id private Long id; @OneToMany(mappedBy = "order", fetch = FetchType.LAZY) private List<Item> items; // getters and setters}@Entitypublic class Item { @Id private Long id; @ManyToOne(fetch = FetchType.LAZY) private Order order; // getters and setters}在上述代碼中,我們通過設(shè)置 @ManyToOne 和 @OneToMany 注解的 fetch 屬性為 FetchType.LAZY 來實現(xiàn)延遲加載。當我們查詢訂單對象時,與之關(guān)聯(lián)的商品列表并不會立即加載,只有當需要訪問該列表時才會進行加載。
需要注意的是,如果在延遲加載模式下訪問了未初始化的集合屬性,就會拋出
org.hibernate.LazyInitializationException 異常。為了避免這種情況,可以將實體類及其關(guān)聯(lián)對象一起加載,或者手動使用 Hibernate.initialize() 方法進行初始化。
緩存是一種用于將經(jīng)常使用的數(shù)據(jù)存儲在內(nèi)存中以便可以更快地訪問的技術(shù)。這可以顯著減少數(shù)據(jù)庫查詢的數(shù)量并提高應用程序的性能。Spring Data JPA 使用 Ehcache、Hazelcast、Infinispan、Redis 等流行的緩存框架為緩存提供內(nèi)置支持。
Spring Data JPA 支持一級緩存和二級緩存。一級緩存是指在同一個事務下,對于相同的實體對象,第二次查詢時直接從緩存中獲取數(shù)據(jù),而不需要再次查詢數(shù)據(jù)庫;二級緩存則是指多個事務之間共享同一個緩存區(qū)域。
下面是使用 Spring Data JPA 緩存的示例代碼:
@Repositorypublic class OrderRepositoryImpl implements OrderRepository { @PersistenceContext private EntityManager em; @Override @Transactional(readOnly = true) public Order findById(Long id) { return em.find(Order.class, id); }}在上述代碼中,我們通過 @PersistenceContext 注解注入了 EntityManager 對象,并在查詢時開啟了只讀事務。由于在同一個事務下,EntityManager 對象會自動緩存查詢過的實體對象,因此當我們多次查詢同一個訂單對象時,第二次查詢將直接從緩存中獲取,而不需要再次查詢數(shù)據(jù)庫。
@Entity@Cacheable(true)@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)public class Order { // ...}@Configuration@EnableCachingpublic class CacheConfig extends CachingConfigurerSupport { @Bean public CacheManager cacheManager() { return new EhCacheCacheManager(ehCacheManager()); } @Bean public EhCacheManagerFactoryBean ehCacheManager() { EhCacheManagerFactoryBean factory = new EhCacheManagerFactoryBean(); factory.setConfigLocation(new ClassPathResource("ehcache.xml")); factory.setShared(true); return factory; }}在上述代碼中,我們使用 @Cacheable 和 @Cache 注解對實體類進行緩存配置,并在配置類中開啟了緩存支持。同時,我們還需要在類路徑下添加一個名為 ehcache.xml 的 Ehcache 配置文件。
需要注意的是,使用二級緩存時需要謹慎,應根據(jù)具體的業(yè)務需求和系統(tǒng)性能要求來選擇使用何種類型的緩存,并合理配置相應的緩存策略。
分頁和排序是用于限制查詢返回的結(jié)果數(shù)量并根據(jù)特定條件對結(jié)果進行排序的技術(shù)。在 Spring Data JPA 中,這些技術(shù)是使用接口實現(xiàn)的Pageable,該接口允許你指定頁面大小、排序標準和頁碼。
下面是使用 Spring Data JPA 分頁和排序的示例代碼:
@Repositorypublic interface OrderRepository extends JpaRepository<Order, Long> { Page<Order> findAll(Pageable pageable);}在上述代碼中,我們通過繼承 JpaRepository 接口來繼承 Spring Data JPA 提供的通用方法,并定義了一個名為 findAll 的方法并添加 Pageable 參數(shù),從而實現(xiàn)分頁查詢功能。在調(diào)用該方法時,可以傳入一個 PageRequest 對象來指定查詢的頁數(shù)、每頁數(shù)據(jù)量以及排序方式等。
@Repositorypublic interface OrderRepository extends JpaRepository<Order, Long> { List<Order> findByStatus(String status, Sort sort);}在上述代碼中,我們定義了一個名為 findByStatus 的方法并添加 Sort 參數(shù),從而實現(xiàn)根據(jù)狀態(tài)字段進行排序的查詢功能。在調(diào)用該方法時,可以傳入一個 Sort 對象來指定排序方式。
需要注意的是,在使用分頁和排序功能時,應盡可能減少查詢的數(shù)據(jù)量,避免出現(xiàn)性能問題。例如,可以使用查詢條件來限制查詢的范圍,或者對數(shù)據(jù)庫表建立索引等方式進行優(yōu)化。
使用 Spring Data JPA 與數(shù)據(jù)庫交互時,優(yōu)化性能以確保有效利用資源和更快的響應時間非常重要。上述幾種技術(shù)可用于實現(xiàn)此目的:
本文鏈接:http://www.tebozhan.com/showinfo-26-10495-0.html四個Spring Data JPA性能提升技巧,讓你的程序更絲滑!
聲明:本網(wǎng)頁內(nèi)容旨在傳播知識,若有侵權(quán)等問題請及時與本網(wǎng)聯(lián)系,我們將在第一時間刪除處理。郵件:2376512515@qq.com
上一篇: 深入探究微服務架構(gòu)下 API 網(wǎng)關(guān)的發(fā)展趨勢
下一篇: 低代碼:告別繁瑣,提速軟件開發(fā)
Copyright ? 2016-2023 天津谷騏科技有限公司 版權(quán)所有 sitemap.xml
違法及侵權(quán)請聯(lián)系:2376512515@qq.com 津ICP備18001702號
 津公網(wǎng)安備 12010102000574號
津公網(wǎng)安備 12010102000574號